Thoughts: Unbiased estimator, what does it actually mean?
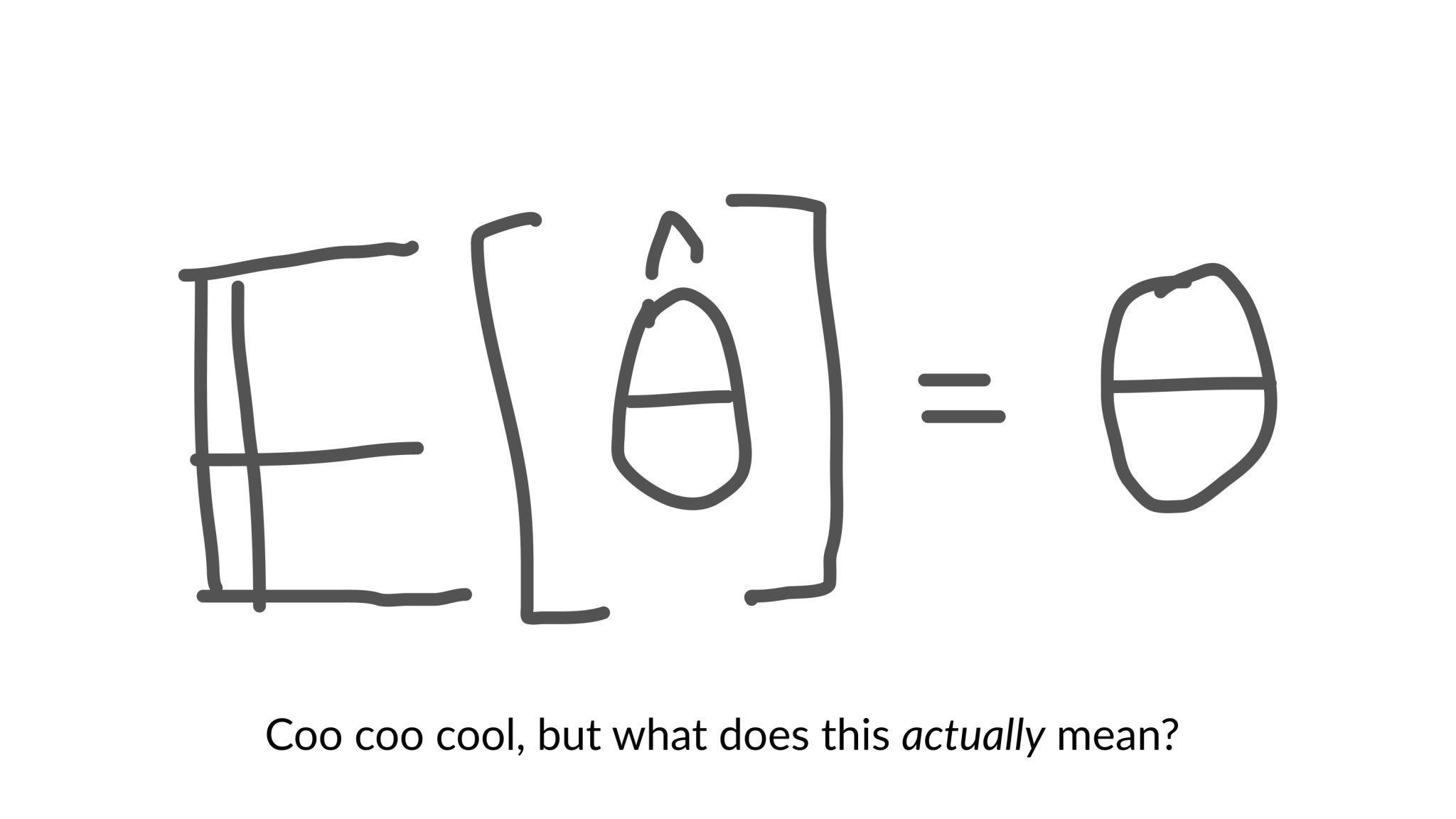
When I first started in data science, I remember hearing about unbiased estimators and wondered what that meant.
In math terms, the concept of an unbiased estimator was not that hard to understand. An unbiased estimator is one whose expected value is equal to the true mean of the parameter we are trying to estimate.
But what does that actually mean?
To give an example, let's say we're estimating the mean of a population. If we pick a random sample of observations, our estimator might overestimate the true population mean, and if we pick another sample, this time the estimator might underestimate the true value.
However, if we could average a large number of estimates from a large number of observations, then this average would be exactly equal to the true value of the parameter!
So, in simple words, an unbiased estimator does not systematically over- or under-estimate the true parameter. 💡