If I had to start learning Data Science again, how would I do it?
A couple of days ago I started thinking if I had to start learning machine learning and data science all over again where would I start? The funny thing was that the path that I imagined was completely different from that one that I actually did when I was starting.
I'm aware that we all learn in different ways. Some prefer videos, others are ok with just books and a lot of people need to pay for a course to feel more pressure. And that's ok, the important thing is to learn and enjoy it.
So, talking from my own perspective and knowing how I learn better I designed this path if I had to start learning Data Science again.
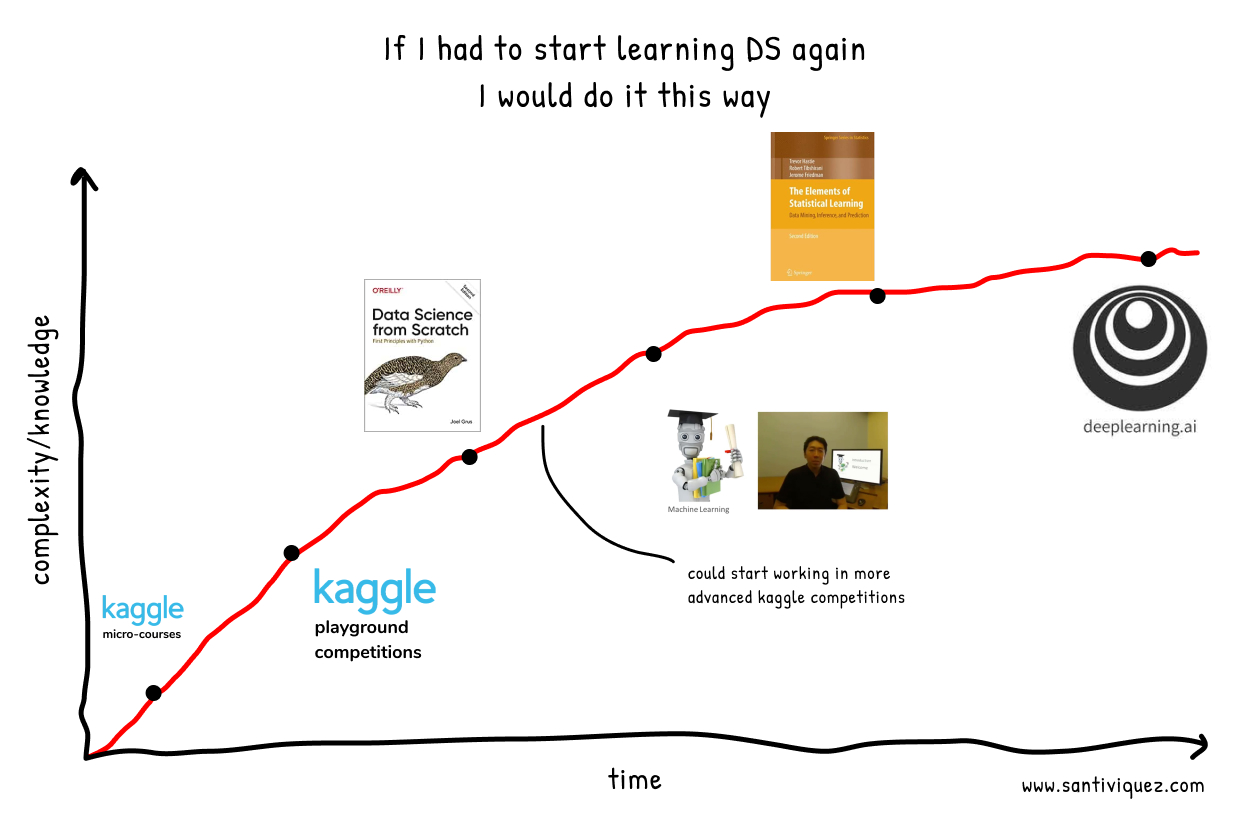
As you will see, my favorite way to learn is going from simple to complex gradually. This means starting with practical examples and then move to more abstract concepts.
Kaggle micro-courses#
I know it may be weird to start here, many would prefer to start with the heaviest foundations and math videos to fully understand what is happening behind each ML model. But from my perspective starting with something practical and concrete helps to have a better view of the whole picture.
In addition, these micro-courses take around 4 hours/each to complete so meeting those little goals up front adds an extra motivational boost.
Kaggle micro-course: Python#
If you are familiar with Python you can skip this part. Here you’ll learn basic Python concepts that will help you start learning data science. There will be a lot of things about Python that are still going to be a mystery. But as we advance, you will learn it with practice.
-
Price: Free
Kaggle micro-course: Pandas#
Pandas is going to give us the skills to start manipulating data in Python. I consider that a 4-hour micro-course and practical examples is enough to have a notion of the things that can be done.
-
Price: Free
Kaggle micro-course: Data Visualization#
Data visualization is perhaps one of the most underrated skills but it is one of the most important to have. It will allow you to fully understand the data with which you will be working.
-
Price: Free
Kaggle micro-course: Intro to Machine Learning#
This is where the exciting part starts. You are going to learn basic but very important concepts to start training machine learning models. Concepts that later will be essential to have them very clear.
-
Link: https://www.kaggle.com/learn/intro-to-machine-learning
-
Precio: Free
Kaggle micro-course: Intermediate Machine Learning#
This is complementary to the previous one but here you are going to work with categorical variables for the first time and deal with null fields in your data.
-
Link: https://www.kaggle.com/learn/intermediate-machine-learning
-
Price: Free
Let’s stop here for a moment. It should be clear that these 5 micro-courses are not going to be a linear process, you are probably going to have to come and go between them to refresh concepts. When you are working in the Pandas one you may have to go back to the Python course to remember some of the things you learned or go to the pandas documentation to understand new functions that you saw in the Introduction to Machine Learning course. And all of this is fine, right here is where the real learning is going to happen.
Now, if you realize these first 5 courses will give you the necessary skills to do exploratory data analysis (EDA) and create baseline models that later you will be able to improve. So now is the right time to start with simple Kaggle competitions and put in practice what you’ve learned.
Kaggle Playground Competition: Titanic#
Here you’ll put into practice what you learned in the introductory courses. Maybe it will be a little intimidating at first, but it doesn’t matter it’s not about being first in the leaderboard, it’s about learning. In this competition, you will learn about classification and relevant metrics for these types of problems such as precision, recall and accuracy.
Kaggle Playground Competition: Housing Prices#
In this competition, you are going to apply regression models and learn about relevant metrics such as RMSE.
By this point, you already have a lot of practical experience and you’ll feel that you can solve a lot of problems, buuut chances are that you don’t fully understand what is happening behind each classification and regression algorithms that you have used. So this is where we have to study the foundations of what we are learning.
Many courses start here, but at least I absorb this information better once I have worked on something practical before.
Learning the fundamentals#
Book: Data Science from Scratch#
At this point we will momentarily separate ourselves from pandas, scikit-learn and other Python libraries to learn in a practical way what is happening “behind” these algorithms.
This book is quite friendly to read, it brings Python examples of each of the topics and it doesn’t have much heavy math, which is fundamental for this stage. We want to understand the principle of the algorithms but with a practical perspective, we don’t want to be demotivated by reading a lot of dense mathematical notation.
-
Link: Amazon
-
Price: $26 aprox
If you got this far I would say that you are quite capable of working in data science and understand the fundamental principles behind the solutions. So here I invite you to continue participating in more complex Kaggle competitions, engage in the forums and explore new methods that you find in other participants solutions.
Online Course: Machine Learning by Andrew Ng#
Here we are going to see many of the things that we have already learned but we are going to watch it explained by one of the leaders in the field and his approach is going to be more mathematical so it will be an excellent way to understand our models even more.
-
Price: Free without the certificate — $79 with the certificate
Book: The Elements of Statistical Learning#
Now the heavy math part starts. Imagine if we had started from here, it would have been an uphill road all along and we probably would have given up easier.
-
Link: Amazon
-
Price: $60, there is an official free version in the Stanford page.
Online Course: Deep Learning by Andrew Ng#
By then you have probably already read about deep learning and play with some models. But here we are going to learn the foundations of what neural networks are, how they work and learn to implement and apply the different architectures that exist.
-
Link: https://www.deeplearning.ai/deep-learning-specialization/
-
Price: $49/month
At this point it depends a lot on your own interests, you can focus on regression and time series problems or maybe go more deep into deep learning.
Now, If you know all of this but want to practice for data science interviews checkout datasciencetrivia.com